
Web Environment Integrity API: An In-depth Analysis
 Rik den Breejen
Rik den BreejenIntroduction
The Web Environment Integrity (WEI) is a proposal by Google engineers that has sparked a lot of debate and misinformation. Many developers and privacy experts are concerned, they are calling it a web DRM for a good reason. As a software engineer, I want to deconstruct this new proposal and expose the potential flaws. From security to privacy, the impacts could be huge.
Preface
Before we continue, some Google employees have been harassed and threatened for being in support of this proposal, I would like to take a moment to tell you to not harass any Google employees or people with opposing views. Threats of violence and abuse are the antithesis to openness. 1
Explaining Web Integrity23
Lets start at the beginning... The Web Environment Integrity API attempts to do the same thing as Captcha's. Simply put, a way to validate that a user is a person, and not a bot.
However as of recent there has been an increased need for a Captcha replacement, because bots have surpassed the solving accuracy of humans on Captchas. That is why these Google employees proposed the Web Integrity API.
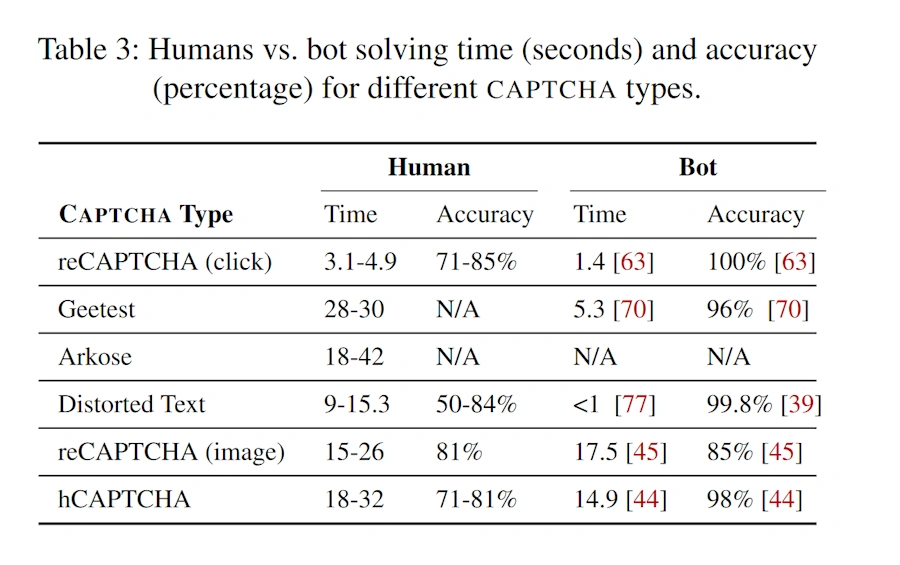
CAPTCHA research paper. Table 3: Humans vs. bot solving time4
Unlike Captchas, the Web Integrity API would take a different approach. They want to have operating systems like Windows implement an integrity component which they call an attester. The attester gathers information from your computer and tries to validate if you are trustworthy enough.
Since these attesters are on the operating system level, they will be mainly controlled by big companies like Google for Android (with Play Integrity API) and Microsoft for Windows.
The data that gets returned from the Integrity API is said to be low entropy5, a fancy way of saying with as little personal information as possible. It will at least contain the attesters verdict and the attesters identity. The attester verdict would likely be a percentage score of how trustworthy the user is. The attester identity could be used by the service to validate if the attester itself it to their standards. Meaning if a service sees for example "Linux attestation" they could decide themselves to accept this attester's trustworthiness.
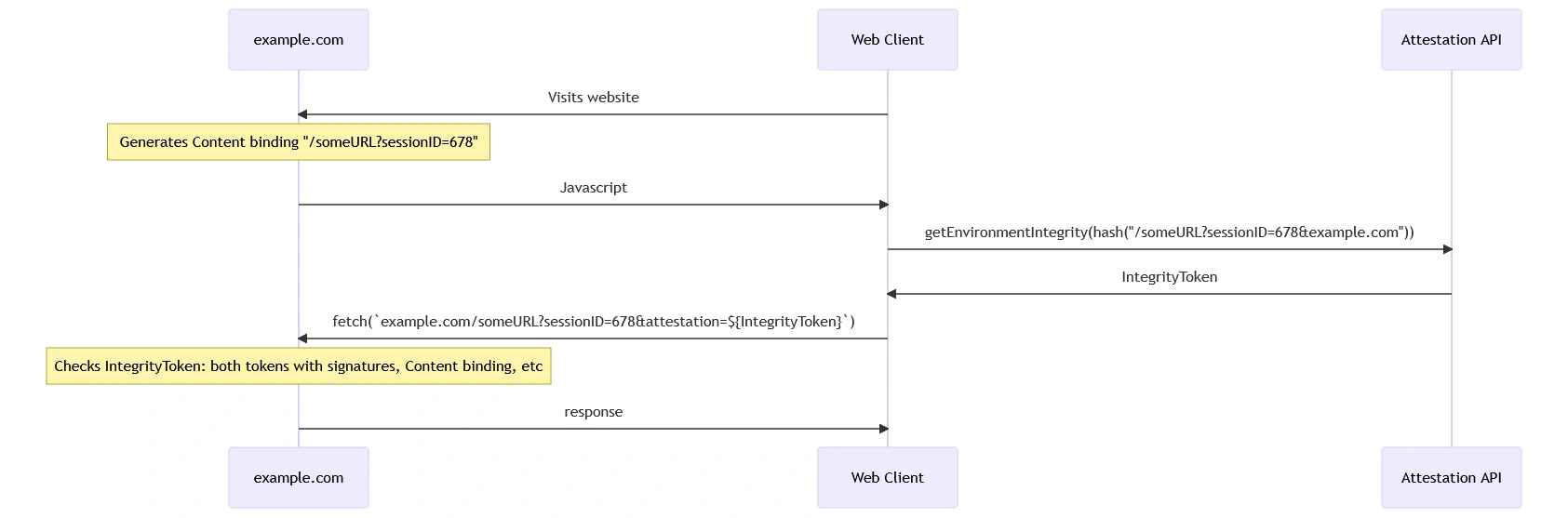
So to summarize, an implementation would make a request to the attesters and then give back a seal of approval (an integrity token). The integrity token would then be used to send requests to the service you are using like YouTube.com. If the service approves of the attester identity then it will accept your request and continue on as normal.
Who Can Be An Attester
The proposal doesn't want to prescribe a specific list of attesters, instead they want to leave it up to the browsers to specify privacy requirements for attesters, so theoretically, anyone could be an attester. They also say that websites/services should be allowed to evaluate each attester's utility on its own merit. Users are also able to opt out of certain attesters if it doesn't meet their quality.
Some potential problems I see with this is that Google Chrome can set requirements on what they need to check on (which could include browser plugins). Making it possible that certain websites exclude people with adblockers.
Another problem has to do with user experience, if a user disables all the privacy invasive attesters and a website requires the user to use one of those, then the user would be blocked out of that website.
Now that we know what the Web Integrity API is and who can be an attester, lets look at what the benefits are (for Google).
The Benefits For You (and For Google)
Under the assumption that there will not be any workarounds, the proposal lists the following benefits to implementing this API.
#1 Easier human validation
For the regular developer this will help with one major thing, it will allow you to check easily who is human, and who is not. It also reduces the amount of effort required from a user, because they don't have to solve a Captcha.
This extends to denial of services (or DDOS) protection. This would make it easier for services like Cloudflare (a service often used for DDOS protection) to verify the incoming requests.
For web games this would mean that they can include human verification in their anti-cheat, making it so that less bots would be in your favorite web games.
This also has huge implications for advertising services. They can validate if a view or a click on an advertisement is real or not, allowing them to sell higher quality website traffic.
#2 Content Protection (DRM)
In theory this API would make it easier for content creators to protect their content from being scraped by bots. This would make bloggers happy, since their content would be less likely to be stolen by an AI. Coincidentally this would also protect AI's like Google's Bard from being scraped.
In Summary
It seems that most of the positive aspects are skewed towards the big tech companies, which means that they would generally be in favor of this proposal.
Explaining the Dangers
Lets go over the downsides of this proposal one-by-one and see what other reasons why Google wants this in web browsers.
#1 Killing Competition / Strangling Other Browsers
Because trustworthiness is based on the environment, which includes the browser, users can't use untrusted browsers. New browsers would be by default not be trusted by attesters. This means that they have to get verified first. If the attester doesn't like the browser's policies they might not validate them. This adds an extra step into creating a new web browser. Making it harder to get into the browser market might kill competition.

Brave and Firefox are browsers that likely don't want to implement it. However because Chromium is such a large part of the browser market they will have to implement it, otherwise they will risk their users not being able to surf the web.

#2 Abusing their Power
Having big tech corporations in the middle of many of the services you use means that they could block you out if the environment isn't to their liking. The proposal does not specify what a trustworthy environment looks like.
We only have a few clues from the proposal itself. It says "if the browser allows extensions, the user may use extensions". It says that you may use extensions, but not that it won't ever test on it. This is further supported by the fact that they say it is also based on the software stack, which includes plugins and extensions.

The paragraph in the explainer talking about if this affects extensions2
Attesters could look at the plugins that you are using on your web browser like an adblocker and decide that it makes you untrustworthy, locking you out of your favorite sites.
This has happened before. IOS and Android have their own form of this called App attest and Play integrity API respectively. A lot of users root their phone, meaning they have full access to their phone's software. Sadly these APIs actively exclude rooted phones from apps like Netflix or banking apps, because the rooted phones are "untrustworthy".
Since browsers on Android would most likely request the Play Integrity as an attester, it will be likely that many rooted users will be excluded from the web entirely.
#3 Privacy / Vulnerabilities
In this proposal there are also a multitude of privacy issues that I would consider vulnerabilities. Including, but not limited to:
- Tracking browser history
- Fingerprinting
- Cross-website tracking
Browser Tracking
Lets look into tracking browser history first. Currently the proposal says that they are looking into it. According to the specification of this feature this will not be allowed. However just because the spec doesn't allow it doesn't mean attestors will not do it anyways. This proposal leaves the crucial question of who will be governing the attestors unanswered.
Currently there is only one proposed solution, limiting the number of attestations that can be looked at for debugging. Which could easily be disabled.
Fingerprinting
On the web we use the term fingerprinting to describe it when a service can identify the person, browser or computer a request is coming from. For attestation the attesters need information from the browser to confirm that your environment is trustworthy. Supposedly this information will be non-identifiable (low entropy)5.
This statement is brought into question since the same proposal says that "Only attesters can include information that can identify users/devices". How can we ensure that attesters do not return responses with personal information? The proposal proposes that attesters would need to publicly state in a readable and verifiable way what they are returning.
For many people, this is not good enough, and creates a large vulnerability for everyone that uses a web browser.
Cross-website tracking
The last vulnerability that the proposal creates is cross-website tracking. Because the integrity token can be stored this vulnerability is technically possible.
A mitigation tactic would be to count on browsers to implement "top-level partitioning", basically disallow storing the token in the browser-storage10. However this still leaves the possibility open for bad websites to get the integrity token and send it to their own server and store it there.
Shouldn't this already have been thought of?
As a developer myself, you should always consider the security risks of any feature before implementing it. In my opinion, prototyping and thinking of the issues later is not up to the quality standard a Google engineer should hold.
That being said, there is a case to be argued that this way was an attempt to get maximum feedback from the community. However that seems to not have worked out well for them.
Is This a Good Faith Proposal?
Many have already debated the question. I will not make a definite statement on this, but I will give you the information to decide for yourself.
The majority of the benefits are in favor of big tech companies, making it undeniable that they would profit greatly if this proposal would go through.
The fact that there are multiple big vulnerabilities that were never thought of before this proposal was submitted and prototyped suggests the fact that the proposers were more concerned with other issues.
A user on the Google Groups discussion of Blink (chrome browser engine) pointed out that the developers had already begun to make changes to the code of Chromium (the foundation of Google Chrome)11. Meanwhile they had closed down all avenues for feedback saying that they are searching for a new one.
The changes in question were made around the 17th and 23rd of July12. These changes enabled the feature for testing in Origin Trial (a opt-in experimentation feature in Chromium). A Blink developer explained how this was the Blink workflow and that they prototype and experiment out in the open13. A page on the official Chromium website seems to support this14. Since this update there haven't been any more code changes on the Web Integrity API15.
Justification Against Implementation
After looking over the pros and cons of the API, I personally think that it should not be implemented.
This API will simply be a temporary fix. It will be a matter of time before people find workarounds. Malicious users could simply use "trustworthy" devices to perform their actions, which leaves the rest of the internet that with all the negatives of the API without any of the benefits.
Not only will it be useless after a while, it will decrease user experience. This system is bound to have false-negatives, frustrating users. Instead of being able to retake a captcha you are stuck with the issue, because no website would find you trustworthy. Besides that it would destroy a lot of backwards compatibility for people using old devices and older browsers. On top of all that it will destroy accessibility on the web by making it harder for users with assistive technologies to access the web.
Lastly, by becoming a middleman on almost every website it will expand the influence big tech companies have over everyone's lives.
In short, the good parts of the proposal will eventually be nullified, while the bad parts will leave a permanent mark on the web.
Current status
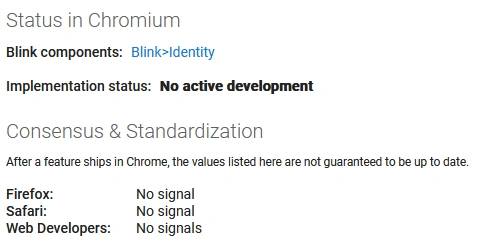
The proposal was met with an overwhelmingly negative reception by developers. Three different browsers have spoken out against this proposal. Mozilla Firefox deeming it contradictory to their principles and vision for the web6. Luckily the status of this proposal is currently not in active development16. The proposers have stated that they will probably be working on it or taking aspects of this proposal later once the buzz around Web Integrity has died down.
Outro
Thanks to the pushback of a lot of developers this proposal has been put on the back-burner. In case this proposal starts up again or they make a proposal with similar elements I encourage everyone to start a respectful conversation that states your case and refrains from abuse and threats. That being said, thank you for reading.
Footnotes
-
Developer threats and abuse: https://groups.google.com/a/chromium.org/g/blink-dev/c/Ux5h_kGO22g/m/0doc7unxAQAJ ↩
-
Proposal explainer: https://github.com/RupertBenWiser/Web-Environment-Integrity/blob/main/explainer.md ↩ ↩2 ↩3
-
Original Proposal: https://github.com/antifraudcg/proposals/issues/8 ↩
-
Captcha: Humans vs Bots study: https://arxiv.org/abs/2307.12108 ↩
-
Low Entropy: https://en.wikipedia.org/wiki/Entropy_(computing) ↩ ↩2
-
Firefox stance: https://github.com/mozilla/standards-positions/issues/852#issuecomment-1648820747 ↩ ↩2
-
Brave stance: https://brave.com/web-standards-at-brave/9-web-environment-integrity/ ↩
-
Vivaldi stance: https://vivaldi.com/blog/googles-new-dangerous-web-environment-integrity-spec/ ↩
-
Browser marketshare: https://gs.statcounter.com/browser-market-share ↩
-
State partitioning: https://developer.mozilla.org/en-US/docs/Web/Privacy/State_Partitioning ↩
-
Pointing out the code changes: https://groups.google.com/a/chromium.org/g/blink-dev/c/Ux5h_kGO22g/m/WJiomHkTAgAJ ↩
-
Most recent commit: https://github.com/chromium/chromium/commit/6f47a22906b2899412e79a2727355efa9cc8f5bd ↩
-
Blink developer reaction: https://groups.google.com/a/chromium.org/g/blink-dev/c/Ux5h_kGO22g/m/gjYbfR_XAgAJ ↩
-
Origin trials: https://www.chromium.org/blink/origin-trials/running-an-origin-trial/ ↩
-
Environment integrity commit history: https://github.com/chromium/chromium/commits/main/components/environment_integrity ↩
-
Proposal status: https://chromestatus.com/feature/5796524191121408 ↩ ↩2